
A Framework for Federal IT Leaders
Federal agencies now have unprecedented access to advanced AI models. GSA’s OneGov initiative, FedRAMP 20x, and top-down AI adoption mandates are accelerating availability across civilian and defense organizations, but promotional pricing and evaluation-tier access will not define the economics of production-scale AI. Sustained API consumption will—and that is where governance becomes essential.
In Part 1 of this series, we showed what happens when agentic AI tools run without observability: 99% token overhead, costs that grew 10x in three months, and a gap between what our gateway measured and what the cloud bill showed.
Part 2 discusses what comes next: not the AI technology, but the governance decisions it requires. Once AI usage scales, federal leaders need to answer three practical questions: how to budget for token usage, how to measure it, and how to keep costs under control. What follows are the three questions every federal IT leader will face on this same path.
“How do I budget for something that doesn’t behave like anything else in my portfolio?”
Traditional cloud spending is predictable. Compute, storage, and bandwidth can generally be forecast with reasonable confidence. AI spending behaves differently because it is shaped by developer behavior, tool selection, and model choice, none of which fit neatly into a traditional forecast. In practice, one developer’s afternoon of experimentation can cost more than a production workload runs in a week.
Federal IT leaders who managed telecom portfolios in the late 1990s will recognize part of this pattern. Billing was metered, pricing was tiered, and costs rose with usage. AI introduces a similar dynamic, but with an important difference: with a phone call, the user controlled the duration. With agentic AI, the developer controls the request, but the tool often determines how many tokens are consumed in fulfilling it. That is why traditional usage forecasting breaks down.
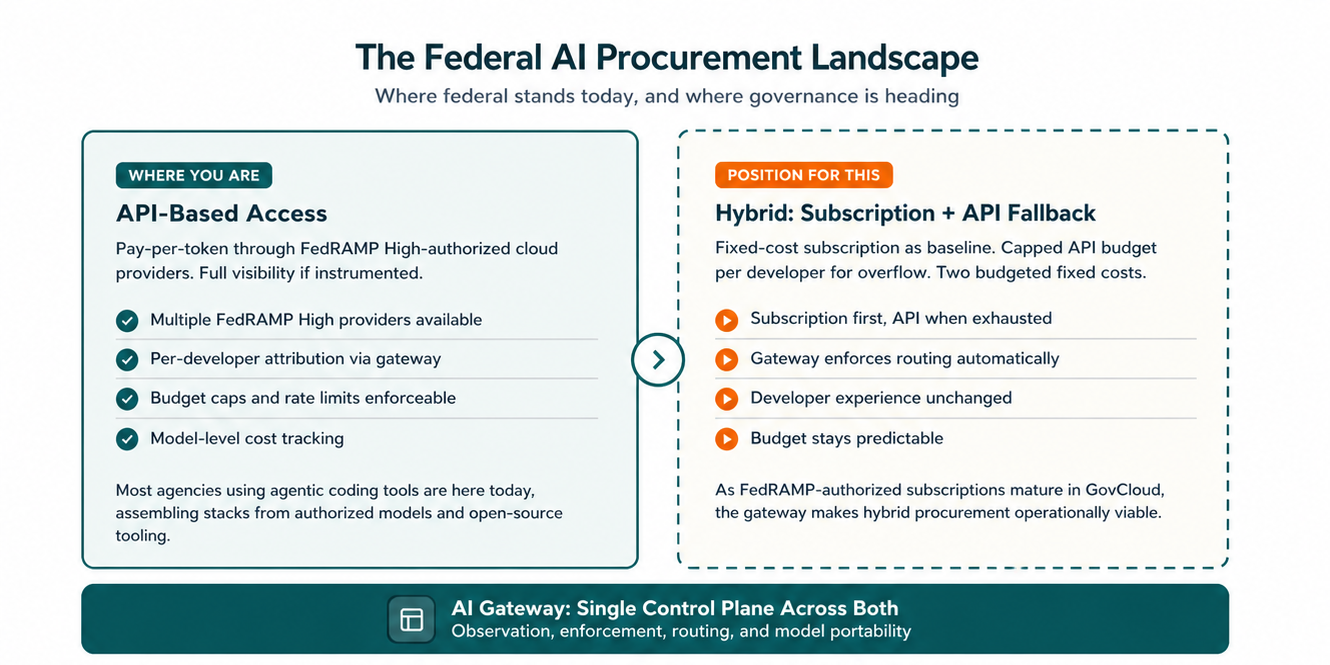
Today, the federal AI procurement landscape falls into three broad categories.
API-based access. This is where most federal organizations are today, particularly for agentic coding workloads. Multiple cloud providers now offer FedRAMP High-authorized API access to advanced models. But subscription options for these tools in compliant environments remain limited, so agencies are often assembling their own stacks from authorized models and open-source tooling. That provides flexibility, but it also puts the burden of cost visibility, attribution, and budget control on the agency.
Subscriptions. Some providers are beginning to offer government-specific subscription tiers with more predictable per-seat pricing. But availability in FedRAMP-authorized, enclave-compliant environments remains limited. These offerings are worth watching, but they are not yet a primary strategy for most agencies.
Hybrid (future state). As compliant subscription options mature, a hybrid model may become more practical: subscription as the fixed-cost baseline, with API access as a capped fallback for overflow or specialized workloads. With a gateway in place, that routing can be enforced automatically, preserving a consistent developer experience while giving agencies more predictable cost control.
The key point is that none of these models govern themselves. Agencies still need a way to attribute usage, enforce spending controls, and manage consumption across providers and tools.
“What should I be measuring and what should my team report?”
This is not primarily a question about dashboards or tools. It is about the small set of data points a federal CIO needs to make sound decisions about AI spending. Here’s what to ask for:
What is our cost per developer per month? Aggregate cloud spend is not enough. Usage patterns can vary dramatically across individuals. In our data, one developer’s monthly cost was 90x another’s on the same team. Without per-developer visibility, it is difficult to forecast budgets, identify outliers, or understand where intervention is needed.
What percentage of our AI spend is visible in our governance tooling? Our gateway captured $47 per developer per month, while our Bedrock bill showed $175+. The difference was usage that never passed through the gateway. If an organization can only see a fraction of its spend, it is only governing a fraction of its risk.
Which models are being used, by whom, and for what? Model choice matters because not all models cost the same. A simple task routed to a premium model can cost 5 to 15 times more than it would on a lighter model. Without model-level attribution, optimization becomes guesswork.
What is the delta between our instrumented data and our cloud bill? This is the governance gap: the difference between what an organization can see and what it is paying for. In our case, that gap exceeded 3x. Closing it is one of the highest-value governance actions available.
How fast is our spend growing month over month? AI adoption curves are steep. Our costs grew 10x in three months. For that reason, the growth rate often matters more than a single point-in-time spending snapshot.
These are governance questions, not technical ones. CIOs should be able to get credible answers to them quickly. If that is not possible today, then the measurement layer is the first investment to make.

“How do I scale adoption without losing control?”
The governance maturity curve has three phases: observe, enforce, and optimize.
Observe. Start with a pilot team and instrument usage through a gateway without imposing limits. At this stage, the goal is visibility, not restriction. Reconcile the gateway data against the cloud bill so you can understand actual usage patterns, including which developers consume the most, which models they use, and how quickly costs are growing. Part 1 of this series covered what RIVA learned in this phase. The investment is modest, and the value of the data is immediate.
Enforce. Once baselines are established, introduce controls. These may include per-developer budget caps, model access policies that define which models are appropriate for which workloads, and rate limits that prevent runaway spend without interrupting productive work. At that point, the gateway becomes a single enforcement point that operates beneath the developer workflow rather than disrupting it.
Optimize. Once data and controls are in place, organizations can make more strategic decisions. Simple tasks can be routed automatically to lower-cost model tiers. Subscription options, as they become available in GovCloud, can be evaluated for specific user profiles. Usage policies can also be designed around session patterns that reduce cache rebuild costs. Over time, these decisions compound into meaningful savings without reducing developer capability.
Governance should not be treated as a constraint on adoption. It is what makes adoption sustainable. Organizations that treat AI governance as an afterthought are more likely to face budget surprises, while those that build it into their adoption strategy from the outset will be better positioned to scale with confidence.
Additional considerations: The federal AI vendor landscape is shifting rapidly. New providers are entering through FedRAMP 20x, procurement vehicles are expanding, and the models available in GovCloud today may not be the same agencies rely on a year from now. A gateway that routes across models and providers is therefore more than a cost optimization tool; it is also an architectural hedge. The goal should be governance that remainsportable across providers rather than locked to one.
Federal buyers should also keep in mind that commercial AI pricing is compressing quickly, but those reductions do not flow into GovCloud and committed-use agreements at the same pace. Governance frameworks should therefore be built around actual contracted rates, not market headlines.
What to Remember
AI spending behaves differently from traditional cloud spending and should be budgeted accordingly. Agencies need to measure the gap between instrumented spend and the cloud bill, and should govern adoption in phases: observe, enforce, and optimize. The gateway is the layer that makes all three possible.
What to Do Next
Start with the five questions. A 30-day gateway pilot across a small team can provide the baseline data needed for budgeting, attribution, and governance.
From there, observation comes first, enforcement second, and optimization third. Each phase builds on the data generated by the one before it, which means agencies do not need to solve everything at once.
At RIVA, we are now moving into the optimization phase by evaluating hybrid procurement models and automated model routing as FedRAMP-authorized options mature. The gateway we built for observation is becoming the control layer for everything that follows.
The organizations that establish these practices now will be the ones that scale AI confidently. The ones that wait are more likely to encounter the problem later in the form of an unexpected cloud bill.
In Part 3, we will share production lessons on model routing, session patterns, and optimization strategies that reduced costs without reducing developer productivity.
Want to learn more about how RIVA is approaching AI governance?
Reach out Bernie Pineau to start a conversation.
Related Articles




