
Retrieval Augmented Generation, or RAG, represents a significant advancement in artificial intelligence technology, especially within the realm of natural language processing. This innovative approach combines the robust capabilities of generative models with an added layer of context retrieval, providing outputs that are not only relevant but deeply informed by a vast array of external data sources. This first part of our series explores the fundamental concepts of RAG, how it operates using Azure AI, and potential applications for the federal sector.
Understanding RAG: A Blend of Retrieval and Generation
What is RAG?
RAG models are designed to enhance the quality and applicability of generated text. Traditional generative models rely solely on their training datasets; however, RAG models extend their knowledge base in real-time by retrieving information from external databases before generating responses. This method allows for more accurate and contextually relevant outputs, effectively addressing the limitations of knowledge confinement in standard AI systems.
The Core Components of RAG Explained
Retrieval: At the onset of the process, when a query is input, RAG models search through a predefined dataset or knowledge base to find relevant information. This retrieval is powered by advanced embedding techniques that transform both the input and the content into vectors in a high-dimensional space, using similarity metrics to pinpoint the most relevant information.
Augmentation: The selected data is then synthesized to augment the input prompt, ensuring that the context provided to the generation model is enriched and pertinent.
Generation: With this augmented input, a generative model (like GPT or BERT) produces a final output that is not only a direct response to the query but is also enhanced by the contextual information gathered during the retrieval phase.
Visualizing RAG Architecture with Azure AI
To provide a clearer understanding of how RAG functions within an Azure AI environment, Figure 1 breaks down the architecture and workflow into two main parts:
Path 1: Document Ingestion and Embedding
![]() The process begins with the ingestion of business-related documents (Orange-1). These can range from reports, emails, policy documents, to any text-rich content relevant to the business or governmental body.
The process begins with the ingestion of business-related documents (Orange-1). These can range from reports, emails, policy documents, to any text-rich content relevant to the business or governmental body.
![]() The documents can be stored in Azure Blob Storage (Orange-2).
The documents can be stored in Azure Blob Storage (Orange-2).
![]() Using an embedding LLM such as text-embedding-3-small, each document is then transformed into embeddings (Orange-3). This involves converting the textual content into a high-dimensional vector representation, which captures the semantic essence of the text.
Using an embedding LLM such as text-embedding-3-small, each document is then transformed into embeddings (Orange-3). This involves converting the textual content into a high-dimensional vector representation, which captures the semantic essence of the text.
![]() The embeddings are then stored within an Azure Search vector (Orange-4). This index is used for similarity searches, allowing the system to locate the most relevant documents based on query embeddings (Part 2).
The embeddings are then stored within an Azure Search vector (Orange-4). This index is used for similarity searches, allowing the system to locate the most relevant documents based on query embeddings (Part 2).
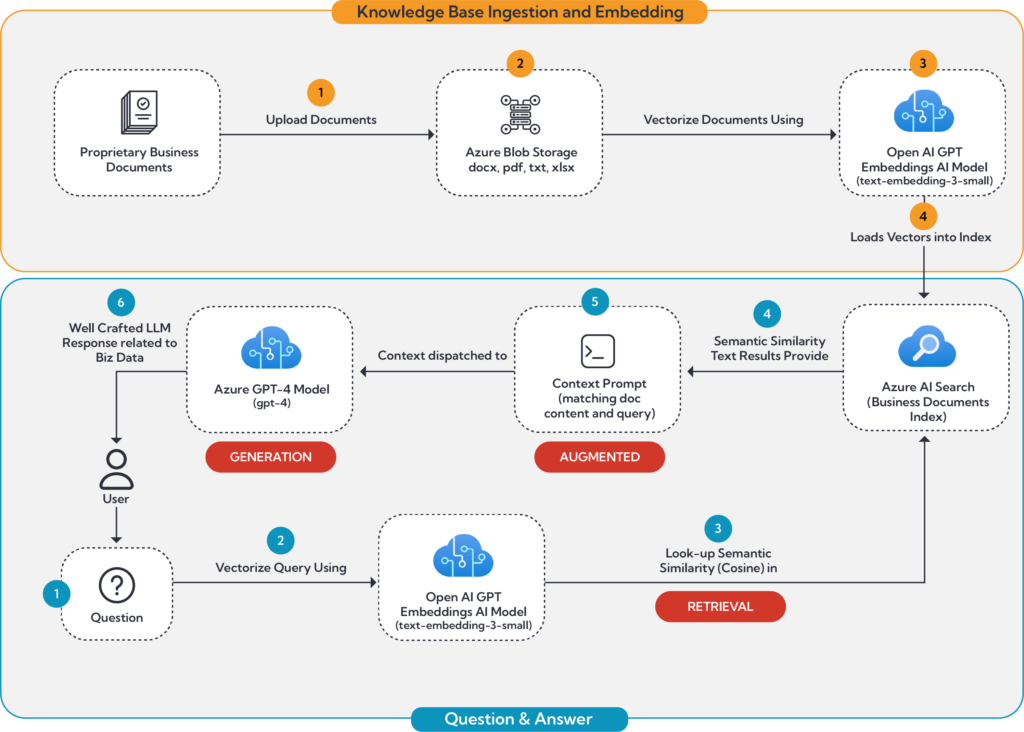
Figure 1: RAG Architecture using Azure AI
Part 2: Question Embedding, Similarity Search and Response Generation
![]() The user poses a question to the system (Blue-1), initiating the retrieval process.
The user poses a question to the system (Blue-1), initiating the retrieval process.
![]() Like document embedding, the question is also converted into a vector form (Blue-2). This embedding process ensures that the question can be compared in the same vector space as the document embeddings.
Like document embedding, the question is also converted into a vector form (Blue-2). This embedding process ensures that the question can be compared in the same vector space as the document embeddings.
![]() Using the indexed embeddings, a similarity search (Blue-3) is conducted to find the most relevant documents. This search leverages similarity measures such as cosine similarity to match the question’s embedding with document embeddings that exhibit the highest degrees of relevance.
Using the indexed embeddings, a similarity search (Blue-3) is conducted to find the most relevant documents. This search leverages similarity measures such as cosine similarity to match the question’s embedding with document embeddings that exhibit the highest degrees of relevance.
![]() The top matching documents are retrieved (Blue-4), and their content is temporarily held for further processing.
The top matching documents are retrieved (Blue-4), and their content is temporarily held for further processing.
![]() The retrieved content, combined with the initial query, is used to formulate a comprehensive context prompt (Blue-5). This enriched prompt integrates both the specific inquiry and the relevant contextual information from the retrieved documents.
The retrieved content, combined with the initial query, is used to formulate a comprehensive context prompt (Blue-5). This enriched prompt integrates both the specific inquiry and the relevant contextual information from the retrieved documents.
![]() This context prompt is then fed into GPT-4, which processes the information and generates a detailed, informed, and contextually relevant answer to the user’s question (Blue-6).
This context prompt is then fed into GPT-4, which processes the information and generates a detailed, informed, and contextually relevant answer to the user’s question (Blue-6).
In the following section, we will explore the Azure AI Studio’s Question and Answer (Q&A) playground. You will notice grammatical errors in these examples; these are intentional to demonstrate the robust contextual understanding capabilities of Large Language Models (LLMs).
RAG in Action: Comparative Analysis using Azure AI Studio
To illustrate the effectiveness of RAG, we present the following video showing the differences in responses with and without the RAG model to the same questions. These examples highlight how RAG provides more detailed, accurate, and contextually enriched answers. This example uses Azure AI Studio’s playground feature to demonstrate the Question and Answers chat bot.
Harnessing RAG for Government Applications
RAG presents multiple applications across various departments within the government, enhancing efficiency, accuracy, and accessibility. Below are some key use cases demonstrating how RAG can be integrated into government functions:
Citizen Services
RAG can assist inventors and patent attorneys by navigating through complex Patent Laws and Rules and submission guidelines. This facilitates a smoother, more informed application process for patents, enhancing user experiences and compliance with regulatory requirements.
Application Development
RAG can analyze and manage vast amounts of application software code stored in SCM repositories like GitHub. It helps in summarizing code, detecting anomalies, and generating automated documentation, thus improving code quality and maintainability.
Risk and Compliance
RAG can be utilized by IT departments to manage and query security documentation such as Security System Plans (SSP), Contingency Plans (CP), Security Impact Analyses (SIAs), and Plans of Actions & Milestones (POA&Ms). It helps validate compliance of these documents and provides suggestions for improvement.
Digital Communications
Content Generation
RAG aids digital communications groups in generating and managing content, recommending accessibility improvements, and enhancing Search Engine Optimization (SEO).
Web Search
RAG improves web search capabilities through context-aware searching, natural language processing, enhanced search relevance, and response summarization. It moves beyond simple keyword searches to include semantic search, which understands the intent and contextual meaning behind queries.
Conclusion and Upcoming Topics
LLMs are incredibly powerful on their own, offering substantial benefits. By integrating RAG, we can further tap into the capabilities of LLMs, using specific data to significantly enhance the accuracy, relevance, and quality of responses. In our upcoming blog posts, we’ll dive deeper into the mechanics of RAG, explore methods to seamlessly incorporate RAG into your existing systems through Prompt Flow, examine case studies in more detail, and discuss the best practices for effectively integrating RAG into your AI solutions.
Reach out if you’re interested in learning more.
Bernie Pineau, RIVA VP Application Services | bpineau@rivasolutionsinc.com
Related Articles




